

DMA это аппаратный модуль в микроконтроллерах STM32, который позволяет периферийным устройствам обмениваться данными с памятью без участия процессора (CPU). Это освобождает процессор от необходимости выполнять рутинные задачи передачи данных, что повышает производительность системы. Позволяет как бы распараллелить программу. ЦПУ будет выполнять свою задачу, а DMA свою.
Важно понять, DMA привязано к конкретному железу на вашем микроконтроллере.Т.е. у каждого модуля DMA есть фиксированная схема соединений с периферией. Это значит, что не любой канал DMA может обслуживать любой UART, SPI или АЦП — есть чёткое соответствие, например DMA1 Channel5 может обслуживать USART1_RX.Эти связи определены внутри микросхемы и изменить их нельзя программно.
Устройство DMA.
В микроконтроллерах STM32 встроен один или несколько контроллеров DMA (Direct Memory Access), в зависимости от серии и модели. Каждый контроллер состоит из нескольких независимых каналов или потоков (streams), которые могут работать параллельно. Количество контроллеров, каналов и их возможности (например, приоритеты, поддерживаемые режимы и источники запросов) указаны в документации к конкретному микроконтроллеру.
В DMA есть понятие каналов и потоков, важно их не путать. Stream (поток) — это физический блок DMA-контроллера, который выполняет передачу данных, каждый из которых может использоваться для независимых передач данных.
Channel (канал) — это логический мультиплексор/маршрутизатор запроса периферии к конкретному потоку.С помощью канала мы выбираем с чем будем работать. А с помощью потока непосредственно происходит работа DMA.
Каналы привязываются к конкретным источникам (периферийным устройствам).
Каждое периферийное устройство связано с конкретным каналом и потоком DMA. Например:
- ADC1 может использовать DMA2, Stream 0, Channel 0.
- USART2_TX может использовать DMA1, Stream 6, Channel 4.
- SPI1_RX может использовать DMA2, Stream 2, Channel 3.
Каждому каналу DMA можно назначить один из четырёх уровней приоритета (Very High, High, Medium, Low), чтобы управлять конфликтами между ними.
Канал привязан к конкретной периферии, а потоки являются независимыми аппаратными ресурсами DMA. Это значит, что один канал может быть использован разными потоками DMA, но одновременно только один поток может работать с этим каналом.
Режимы работы.
Существует два режима работы DMA. Память/память и память/устройство (и устройство/память).
Память/память.
Суть: DMA копирует данные из одного участка памяти в другой, не обращаясь к периферии. Источник и приёмник — оба находятся в SRAM, Flash или другом адресном пространстве памяти. Удобно использовать для быстрого копирования большого объёма данных.
Память/устройство и устройство/память
Пожалуй ключевым моментом для понимания работы DMA является то что вся работа происходит через запросы. В случае, когда мы хотим что-то передать на устройство ( UART,SPI и т.д.) DMA отправляет запрос на это устройство и если оттуда получен положительный ответ, то DMA начинает передачу данных. В случае если у нас вариант устройство/память, то DMA будет ожидать запрос от устройства, после чего будет начата передача данных из устройства в память.
Прерывания DMA.
В DMA существует три вида прерываний.
- Transfer Complete (TC) — Передача завершена. Вызывается, когда весь заданный объем данных был передан.Это то, что обычно используют, чтобы понять: «копирование закончено — можно обрабатывать данные
- Half Transfer Complete (HT) — Половина передачи завершена. Срабатывает, когда DMA передал половину буфера.Очень полезно, если нужно обрабатывать данные «на лету» — пока вторая половина ещё заполняется Например: кольцевой буфер от АЦП или UART.Можно заполнять переменную передачи по половине, а значит организовать постоянную и быструю передачу.
- Transfer Error (TE) — Ошибка передачи.
Пример Memory-to-Peripheral.
Сделаем аппаратный ШИМ с использованием DMA и плавно позажигаем светодиод.
Идея работы следующая. Как мы уже знаем вся работа блока DMA основана на запросах. Нам необходимо изменять коэффициент заполнения нашего ШИМ. Значит выставим настройки так, чтобы наш блок ШИМ отправлял запрос к DMA, получал оттуда значение которое и будет коэффициентом заполнения.Запрос к блоку DMA будет посылаться в момент захвата/сравнения. И всё это без участия CPU.
Выберем таймер 4 , 1 канал, вывод PD13 . На нашей плате это зелёный светодиод. Шину APB1 с которой работает наш таймер настроим на 16 МГц.
Настроим ШИМ.
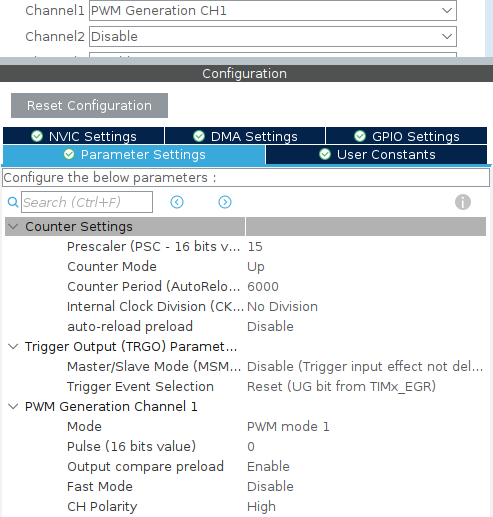
В настройках таймера выберем PWM Generation CH1 для генерации аппаратного ШИМ и выставим следующие настройки.
Prescaler 15.Counter Period 6000.Pulse 0.
Настроим DMA.
Кликаем на DMA Settings нашего таймера TIM4.
![]()
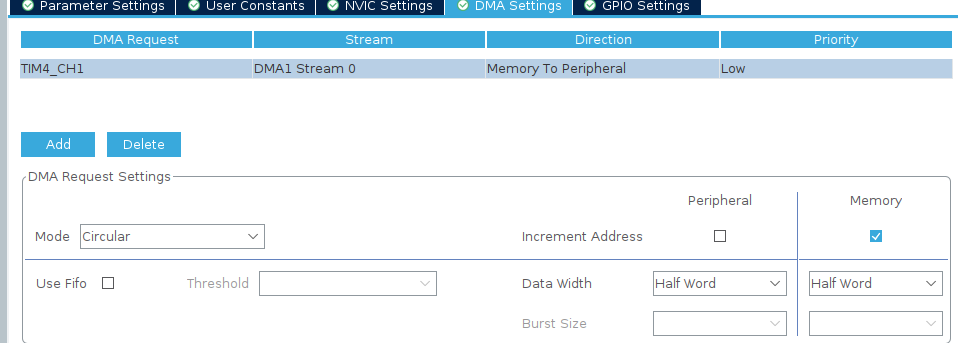
Добавляем DMA request. Нажимаем кнопку Add. Выбираем DMA Request — TIM4_CH1.
Stream — DMA1 Stream 0. Direction — Memory To Peripheral.
Происходит следующее.
Когда вы выбираете TIM4_CH1, вы используете DMA для автоматического обновления регистра CCR1 (Capture/Compare Register 1), который определяет ширину импульса (длительность высокого уровня) сигнала ШИМ на канале 1, т.е. значение Pulse.
- Таймер считает от нуля до ARR (counter Period)
- В моменте когда счётчик таймера становится равным CCR срабатывает событие и генерируется запрос в DMA.
- DMA записывает новое значение в CCR (Pulse)
- Таймер досчитывает до ARR (counter Period)
- Процесс повторяется но с уже новым значением CCR(Pulse)
Stream-DMA1 Stream 0. Выбор потока.Для TIM4_CH1 доступен только один поток:DMA1 Stream 0.
Direction — Memory To Peripheral.Выбираем Memory To Peripheral т.к мы передаем из памяти в периферию (в регистр TIM4_CCR1).
Priority — Low.Priority (приоритет) определяет важность этого DMA-потока по отношению к другим потокам DMA. Оставляем Low.
Mode — Circular.В режиме Circular DMA автоматически начинает новую передачу после завершения предыдущей, без необходимости перезапуска.
Increment Address — Memory.Позволяет DMA работать с массивами, передавая данные последовательно из каждой ячейки памяти. Нужно включить если работаем с массивом. Если же нужно передать одно одинаковое значение то выбираем Peripheral.
Fifo — выключено.FIFO (First-In-First-Out) — это буфер памяти внутри DMA-контроллера, который временно хранит данные перед их передачей. Полезно на больших объёмах данных.
Data Width — Half Word.Регистр TIM4_CCR1 — 16-битный а Half Word используется, если периферийное устройство (например, таймер или регистр периферии) работает с 16-битными данными. В нашем случае число от 0 до 6000.
Получили вот такие настройки:
Теперь необходимо заполнить массив значениями ширины импульса которые мы будем передавать.
void Fill_PWM_Values() {
int index = 0;
// Рост яркости (от 0 до MAX_PULSE)
for (uint16_t pulse = 0; pulse <= MAX_PULSE; pulse += STEP) {
pwm_values[index++] = pulse;
}
// Спад яркости (от MAX_PULSE до 0)
for (uint16_t pulse = MAX_PULSE; pulse > 0; pulse -= STEP) {
pwm_values[index++] = pulse;
}
}
MAX_PULSE это максимальная длина импульса равная периоду. У нас это 6000.
Запускаем ШИМ.
HAL_TIM_PWM_Start_DMA(&htim4, TIM_CHANNEL_1,(uint32_t *)pwm_values, ARRAY_SIZE);
Определим PD12 как выход TIM4_CH1.
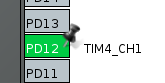
В результате длина импульса ШИМ меняется, на заданное нами значение из массива pwm_values. Это хорошо видно на примере нашего светодиода который плавно зажигается и гаснет и всё это без участия центрального процессора.
Пример Memory To Memory.
Сделаем копирование из памяти в память на примере массива чисел, а затем выведем этот массив на дисплей.
Открываем вкладку System Core — DMA — MemToMem.

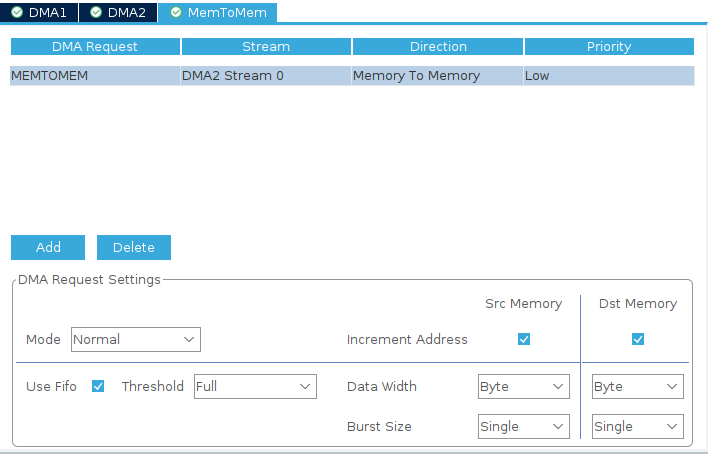
Нажимаем кнопку добавить и выбираем MEMTOMEM. Затем выбираем свободный поток и выставляем его настройки.
Mode -Normal.
Increment Address — Увеличение адреса источника и приёмника после каждой передачи одного элемента. Мы передаем массив, нам это надо.
Use Fifo — включим, для увеличения скорости передачи.
Threshold(размер буфера) — оставим Full.
Data Width — Byte. Будем передавать числа от 0 до 100 так что вполне поместится.
Burst Size(количество пакетов) — Single.
Включим прерывания
![]()
Программный код
Создадим два массива, один заполним значениями а другой оставим пустым. Заполняем первый массив числами.
void fillStartArr() {
for (uint8_t i = 0; i < ARRAY_SIZE1; i++) {
arrToDMA[i] = i; // заполняем от 0 до 99
}
}
Зарегистрируем callback который сработает по завершению передачи memory-to-memory.
HAL_DMA_RegisterCallback(&hdma_memtomem_dma2_stream0, HAL_DMA_XFER_CPLT_CB_ID, dma_m2m_callback);
- &hdma_memtomem_dma2_stream0 указатель на структуру DMA_HandleTypeDef, которая описывает твой конкретный DMA-поток/канал
- HAL_DMA_XFER_CPLT_CB_ID Специальный enum, который указывает, для какого события мы регистрируем обработчик. В нашем случае завершение передачи.
- dma_m2m_callback Указатель на твою функцию-обработчик, которая будет вызвана, когда произойдет событие
Важно чтобы callback был зарегистрирован до старта DMA.
Напишем короткую функцию обработчик.
void dma_m2m_callback(DMA_HandleTypeDef *hdma)
{
dmaTransferComplete = 1;
}
При вызове функции устанавливаем переменную завершения передачи в 1.
Запустим копирование из одного массива в другой
if (HAL_DMA_Start_IT(&hdma_memtomem_dma2_stream0,
(uint32_t)arrToDMA,
(uint32_t)recArrToDMA,
ARRAY_SIZE1) != HAL_OK)
{
Error_Handler();
}
Затем в цикле while проверяем состояние переменной dmaTransferComplete и если оно равно 1 запускаем функцию вывода на дисплей.
while (1) {
if (dmaTransferComplete) {
HAL_Delay(1000);
sendArrNumber(counter);
counter++;
}
/* USER CODE END WHILE */
/* USER CODE BEGIN 3 */
}
Тело функции
void sendArrNumber(loc_counter)
{
char buffer[10]; // Буфер для хранения строки
sprintf(buffer, "%d", arrToDMA[loc_counter]); // Преобразование числа в строку
ST7735_DrawString(0, 3*10, buffer, Font_11x18, ST7735_GREEN, ST7735_BLACK);
}
В итоге мы заполнили второй массив данными с помощью DMA. При этом сам программный код пошёл выполняться дальше, параллельно с передачей данных, что очень удобно особенно если у вас большой объем данных.